Ray Train
Axolotl supports using Ray as an alternative to accelerate for orchestrating training. This is especially useful for multi-node training since you only have to setup code and dependencies in a single node and launch training as if you were using a single node.
With the --use-ray CLI flag, Axolotl will use Ray Train’s TorchTrainer to run training.
Ray cluster setup
A prerequisite using the Ray Train integration is to setup a Ray cluster on your desired node(s). For a detailed guide on how you can get started with ray clusters, check the official Ray docs here.
Every Ray cluster has one head node and a set of worker nodes. The head node is just like any other worker node, but it also runs certain special processes related to scheduling and orchestration. Ray-enabled scripts are run on the head node and depending on the resources (number of CPUs, GPUs, etc) they request, will be scheduled to run certain tasks on the worker nodes. For more on key concepts behind a Ray cluster, you can refer this doc.
Sanity check
To run a sanity check on whether your ray cluster is setup properly, execute the following on the head node:
ray statusThe output should have a summary of your Ray cluster - list of all the nodes in your cluster, the number of CPUs and GPUs in your cluster, etc. For example, if you have a cluster with 1 CPU-only head node and 2 4xL40S worker nodes, the output can look like this:
Node status
---------------------------------------------------------------
Active:
1 head
Idle:
2 4xL40S:48CPU-384GB
Pending:
(no pending nodes)
Recent failures:
(no failures)
Resources
---------------------------------------------------------------
Usage:
0.0/96.0 CPU
0.0/8.0 GPU
0B/800.00GiB memory
0B/229.57GiB object_store_memory
Demands:
(no resource demands)You should also be able to see the same on the Ray dashboard.
Configuring training with Ray Train
You can find an example configuration at configs/llama-3/lora-1b-ray.yaml.
The key parameters to note here are:
use_ray: true
ray_num_workers: 4
# optional
resources_per_worker:
GPU: 1use_ray: This is the flag that enables the Ray Train integration. You can either use the corresponding--use-rayflag in the CLI or setuse_rayin the config file.ray_num_workers: This is the number of workers/GPUs to use for training.resources_per_worker: This is the Ray resource request for each worker. This can be used to request a specific GPU type or a custom resource for each worker. For example, if your ray cluster has GPUs of different types, and you only want to use NVIDIA L40S GPUs, you can do
resources_per_worker:
accelerator_type:L40S: 0.001Launching training
You can simply run the following command on the head node:
axolotl train examples/llama-3/lora-1b-ray.yml --use-rayThis will launch training on the head node and workers will be scheduled automatically by Ray Train to run on the appropriate head or worker nodes.
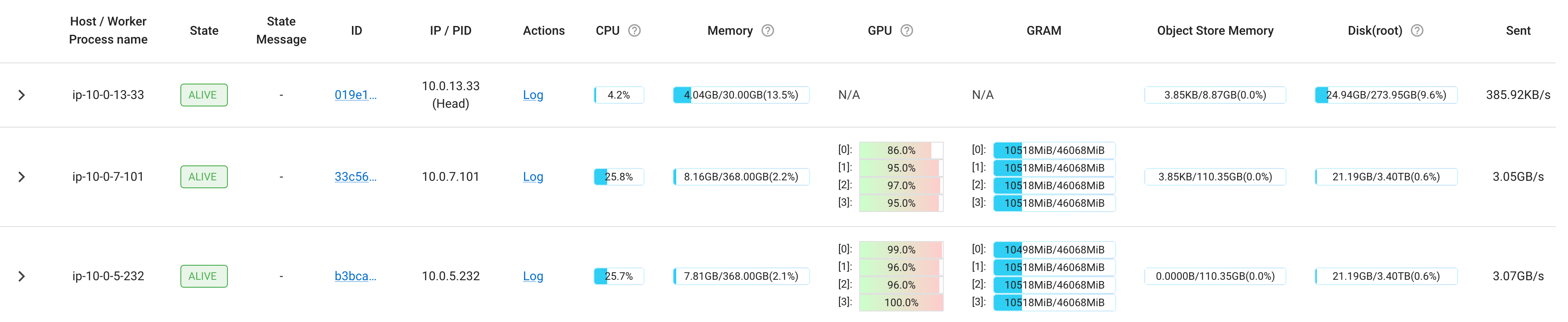
You can also monitor training progress on the Ray dashboard.
Coming back to the example on a Ray cluster with 1 head node and 2 4xL40S worker nodes, let’s say you want to make use of all 8 GPUs. You would be able to just set ray_num_workers: 8 and run the previous command. The Cluster tab will show the following: