Multipack (Sample Packing)
Visualization of Multipack with Flash Attention
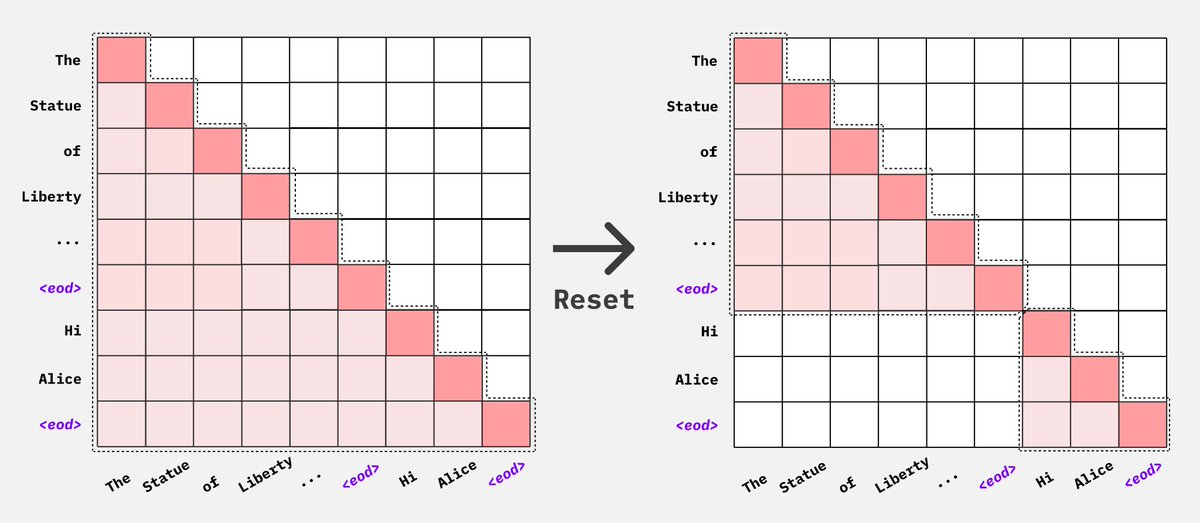
Because Flash Attention simply drops the attention mask, we do not need to construct a 4d attention mask. We only need to concatenate the sequences into a single batch and let flash attention know where each new sequence begins.
4k context, bsz =4, each character represents 256 tokens X represents a padding token
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
[[ A A A A A A A A A A A ]
B B B B B B ]
C C C C C C C ]
D D D D ]]
[[ E E E E E E E E ]
[ F F F F ]
[ G G G ]
[ H H H H ]]
[[ I I I ]
[ J J J ]
[ K K K K K]
[ L L L ]]after padding to longest input in each step
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
[[ A A A A A A A A A A A ]
B B B B B B X X X X X X ]
C C C C C C C X X X X ]
D D D D X X X X X X X ]]
[[ E E E E E E E E ]
[ F F F F X X X X ]
[ G G G X X X X X ]
[ H H H H X X X X ]]
[[ I I I X X ]
[ J J J X X ]
[ K K K K K ]
[ L L L X X ]]w packing ( note it’s the same effective number of tokens per step, but a true bsz of 1)
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
[[ A A A A A A A A A A A B B B B B
B C C C C C C C D D D D E E E E
E E E E F F F F F G G G H H H H
I I I J J J J K K K K K L L L X ]]cu_seqlens: [[ 0, 11, 17, 24, 28, 36, 41 44, 48, 51, 55, 60, 64]]
Multipack without Flash Attention
Multipack can still be achieved without Flash attention, but with lower packing efficiency as we are not able to join multiple batches into a single batch due to context length limits without flash attention. We can use either Pytorch’s Scaled Dot Product Attention implementation or native Pytorch attention implementation along with 4d attention masks to pack sequences together and avoid cross attention.